20,000 Leagues Under The Sand: Part 5
You may have a tricked-out sandbox that logs host activity, does packet capture and IDS, and will make you a slice of toast, but none of the bells and whistles will do you any good without collecting the information and putting it in front of your eyes. The techniques required will test your knowledge of network and file system forensics, as well as your skill with code. Let’s start with an easy one.
Suricata logs
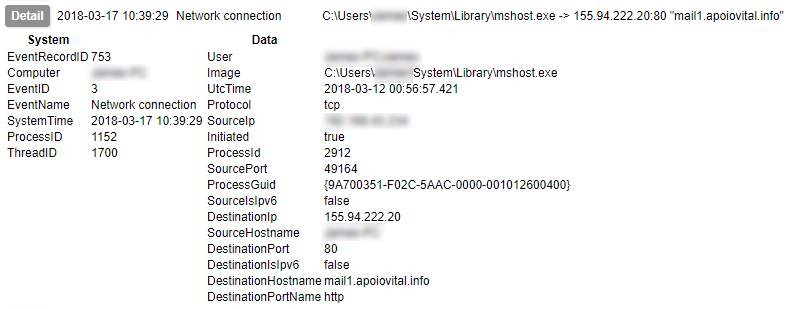
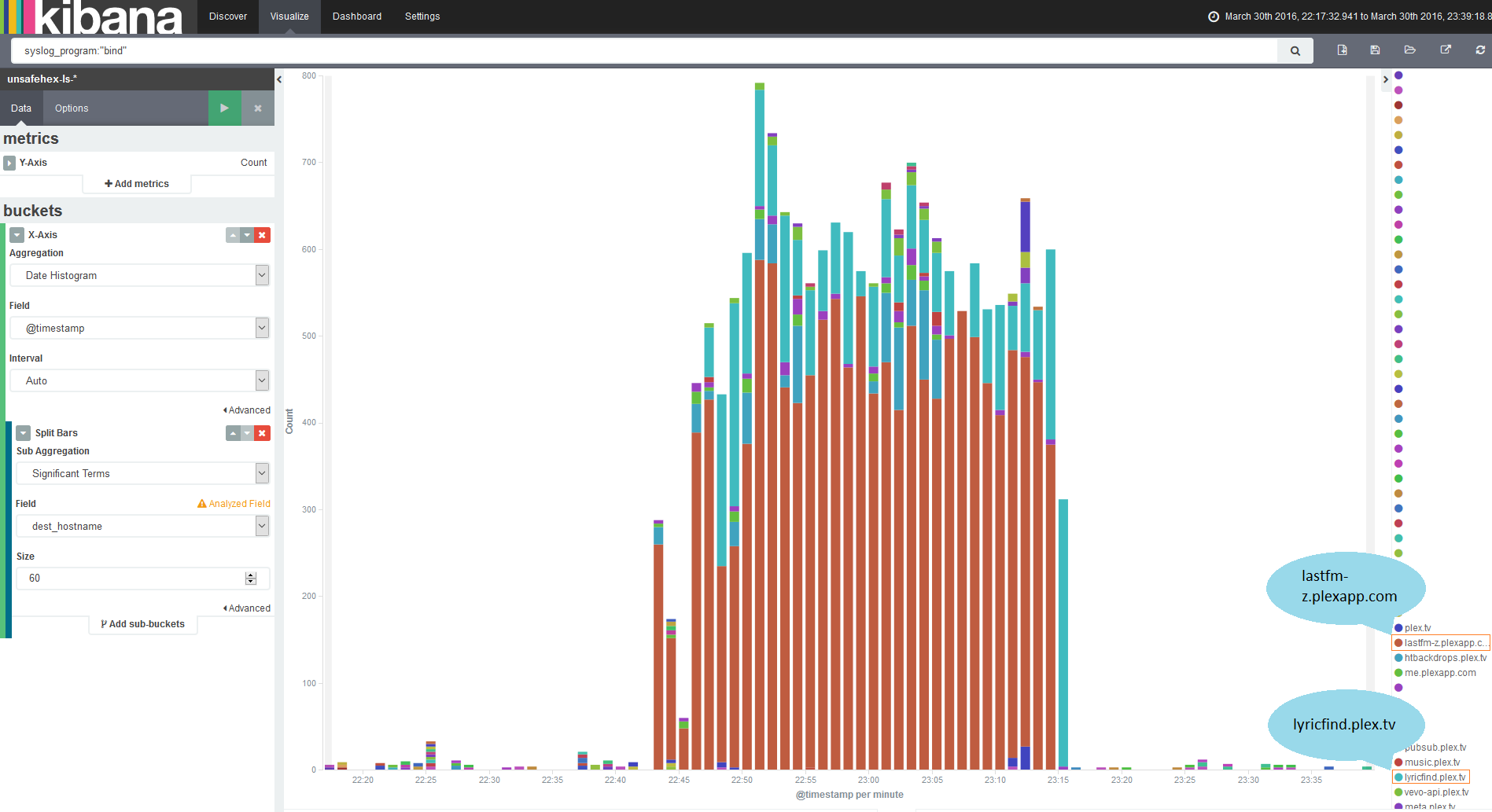
If you have followed the suggestions made earlier in this series, Suricata will be writing events to files in /var/log/suricata/ in JSON form, one object per line. This lends itself to ease of use; pretty much any language will have a good JSON parsing library. All you will need to do is filter for entries based on the timestamp being within the period you were running your malware sample.
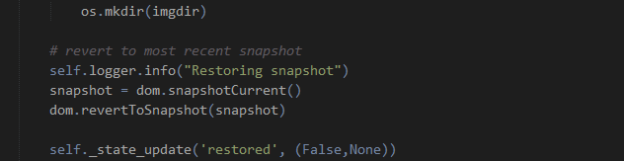
Be aware that the Suricata log does not get truncated unless you have specified. If you read and filter the log using the simplest method (line-by-line read from the start, parsing each event then filtering), this will eventually become very slow. You should consider rotating the file, either yourself or using Suricata’s built in rotation, and make sure that your parsing and filtering takes account of this rotation.
Packet capture
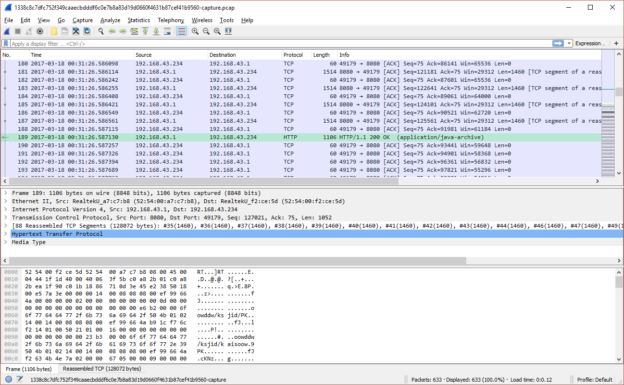
As mentioned in the post discussing networking, you can either create a per-run packet capture as part of your code (assuming your language has the appropriate libraries), or a systemwide one which you can then extract portions of.
If you only ever plan to have one guest VM sandboxing malware at a time, the per-run capture should be fine and relatively simple. If you are slightly nuts ambitious like me and want to design for the possibility of several in parallel, a systemwide capture would be more suitable. Again, depending on the way you have organised capture, you should make sure your code accounts for the rotation of the pcaps.
Host activity/event logs
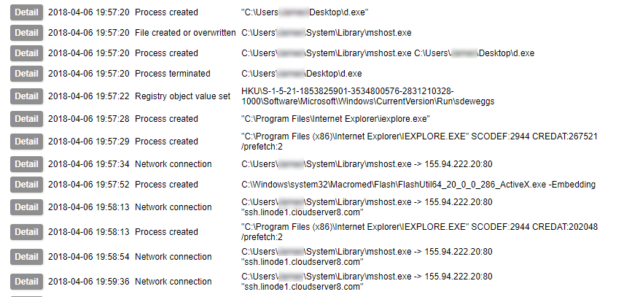
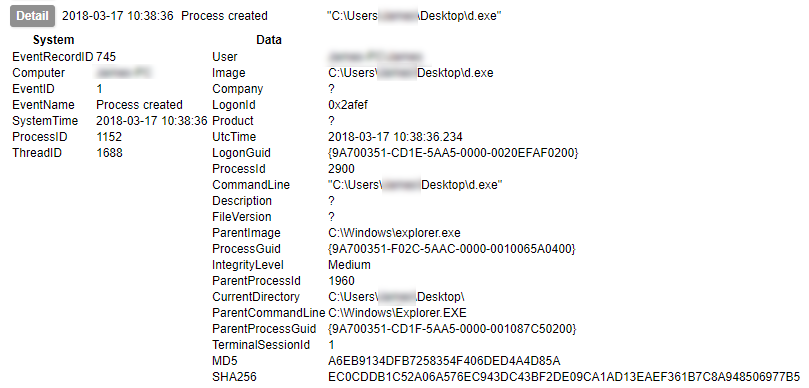
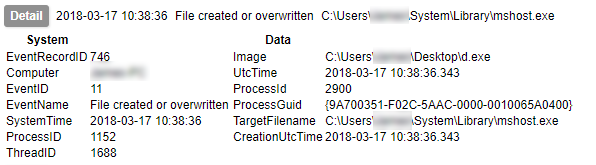
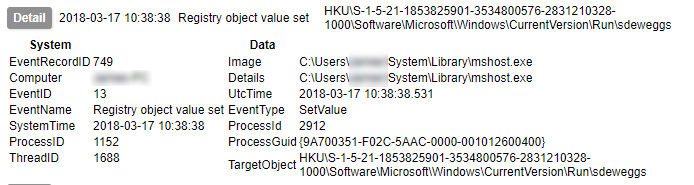
Early on in this series I waxed lyrical about the advantages of Sysmon. I am not going to contradict any of that here, but collecting its output is not as simple as you might think. Windows event logs get written to EVTX files, but not necessarily immediately. Therefore although an event may be generated, its presence in the EVTX file is not guaranteed. Under testing I have found that not even a shutdown is a guarantee of the events being written to the file. The only method I have found to be 100% reliable is to query the Windows Event Log API¹. Therefore, to collect Sysmon logs in a reliable fashion, you need to be able to use the Windows API.
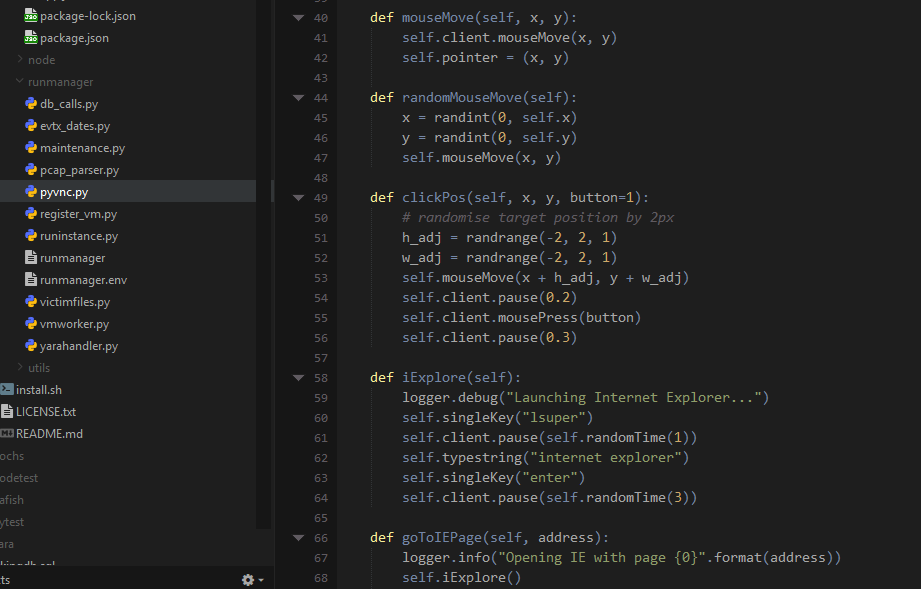
I am aware of two methods for doing this. The first is to write a program which queries the API, and run that in your sandbox. You can then write the data to a file, or send it out of the sandbox immediately. To send it out of the sandbox you could have a service on the host listening on the virtual network interface, such as an FTP or HTTP server.
The second method would be to use Windows Event Forwarding. This is a tremendously useful technique for blue teamers and comes highly recommended by Microsoft staff. It does, however, require you to have a second Windows host on which to collect the events, which may not be an option for you. Most documentation you will find on this will refer to setting it up in an Active Directory environment, however it is also capable of running in workgroup-only systems.
¹ I strongly suspect that the events are being written to temporary files but at the time of writing this is little better than a hunch. I’ll chase down my suspicion at some point and if it’s right there’ll be a new post about my findings.
Filesystem collection
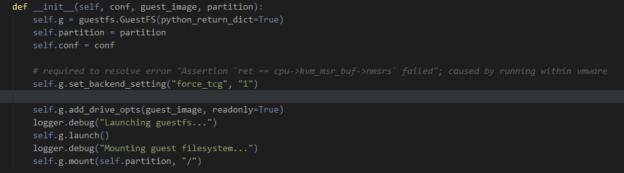
Getting events is a huge win, and might well be all you need; but why not go one step further? Malware drops and modifies files and writes to the registry, and if you could get your hands on that evidence, it could be invaluable. Another of the reasons for choosing LibVirt/QEMU as my hypervisor was the availability of python bindings for LibGuestFS, allowing me to directly mount and read QEMU disk images. However, you should still be fine with other hypervisors: VMWare also provides a utility for this, and VirtualBox can apparently be mounted as a… network block device? Please can I have some of whatever Oracle have been smoking, because it’s clearly the good shit.
Detailed coverage of the options for filesystem evidence collection could run to several blog posts of its own, so I won’t go into everything here. However, I will describe three approaches, each with their own advantages and drawbacks.
- Diffing from a known-good state
The slowest, but most comprehensive method. Requires building a comprehensive catalogue of the hashes of all files on the disk prior to malware execution, and another one after, and identifying the differences. Not recommended unless you are truly desperate to roast your CPU with hash calculations.
- Metatadata-based selection
Since you know the lower and upper time bounds for possible activity by the malicious sample, you can walk the directory tree and select only items which have been changed or created in that period. Relatively quick, but some malware is known to modify the MFT record with false created/modified values, known as ‘timestomping’.
- Key items and locations
The majority of malware activity is limited to just a few locations. Taking a copy of the user directory, and SYSTEM and SOFTWARE registry hives, plus a couple of other items, would capture the traces left by most samples you might ever run.
There is a final option for collection of file-based evidence, and that is to use a host agent which collects the files as the malware writes them. The above methods would fail to capture a file that has been created and subsequently removed. In an earlier post I mentioned that if you were so inclined, you could write code which would monitor API calls yourself. Doing this would also give you the ability to capture temporary files in addition to the ones which are left behind.
Hopefully you now have an idea of the approaches you can use to gather useful information from the execution of a malware sample without the need for manual intervention. The final post in my series considers anti-analysis techniques and countering sandbox evasion.